
BEAVERTON, OR – March 14, 2017 – The Heterogeneous System Architecture (HSA) Foundation continues to expand its Academic Partnership Program with the addition of Finland-based Tampere University of Technology (TUT) as an HSA Academic Center of Excellence. TUT is in Tampere, about 170 km (105 miles) north of Helsinki.
TUT is now the third European university accorded this distinction — in December, the Foundation announced that Technische Universitaet (TU) Darmstadt, and Friedrich-Alexander-University Erlangen-Nurnberg (FAU), both in Germany, were named Academic Centers of Excellence; Northeastern University was the first in North America.
HSA is a standardized platform design that unlocks the performance and power efficiency of the parallel computing engines found in most modern electronic devices. It allows developers to easily and efficiently apply the hardware resources — including CPUs, GPUs, DSPs, FPGAs, fabrics and fixed function accelerators — in today’s complex systems-on-chip (SoCs).
“We’re excited to have TUT on board as an Academic Center of Excellence and look forward to collaborating with the university on several projects,” said HSA Foundation President Dr. John Glossner. “TUT is the forefront of research in areas that intersect closely with heterogeneous computing such as intelligent machines and networked systems.”
“The HSA ecosystem is growing rapidly not only in Finland, but throughout Europe,” said HSA Foundation Chairman and Managing Director Greg Stoner. “TUT has a long-established reputation encompassing an array of innovative technologies. Our members — and the global tech community — will benefit greatly from this burgeoning partnership.”
Jarmo Takala, a professor in the TUT Faculty of Computing and Electrical Engineering, added that the research group is currently working on an open source implementation of the OpenCL standard, called the Portable Computing Language project.
“We’re also going to add support for HSA specs and create a complete tool flow for HSA runtime customized accelerators based on transport-triggered architecture, and open source design tools for these processors, known as the “TTA-based Co-Design Environment” added Takala.
Dr. Pekka Jääskeläinen, who is currently working at TUT as a postdoctoral researcher funded by the Academy of Finland and also involved in various HSA- related activities, said adopting HSA standards “is enabling us to build well-documented IP interfaces to SoC components. HSA is also providing a framework for more studies related to programmer-productivity challenges still hindering heterogeneous platform adoption.”
About TUT
Established in 1965 as a subsidiary of Helsinki University of Technology, TUT became an independent university in 1972. Today, more than 8,300 undergraduate and postgraduate students attend TUT. Of these, about 1,500 students from more than 60 countries are currently pursuing studies. TUT is a sought-after partner for collaborative research and development projects with business and industry worldwide.
About the HSA Foundation
The HSA (Heterogeneous System Architecture) Foundation is a non-profit consortium of SoC IP vendors, OEMs, Academia, SoC vendors, OSVs and ISVs, whose goal is making programming for parallel computing easy and pervasive. HSA members are building a heterogeneous computing ecosystem, rooted in industry standards, which combines scalar processing on the CPU with parallel processing on the GPU, while enabling high bandwidth access to memory and high application performance with low power consumption. HSA defines interfaces for parallel computation using CPU, GPU and other programmable and fixed function devices, while supporting a diverse set of high-level programming languages, and creating the foundation for next-generation, general-purpose computing.
Follow the HSA Foundation on Twitter, Facebook, LinkedIn and Instagram.
Contact Information
Contact:
Neal Leavitt
Leavitt Communications
(760) 639-2900
neal@leavcom.com
Category Archives: Newsflash
The HSA Foundation expands its Academic Partnership Program

Entrepreneur Podcast Network: http://epodcastnetwork.com/the-hsa-foundation-expands-its-academic-partnership-program/
Dr. John Glossner, President of HSA or The Heterogeneous System Architecture a non-profit whose goal is making programming for parallel computing easy and pervasive again joins Enterprise Radio to discuss more about the foundation, the overall benefit and the new partnership.
Listen to host Eric Dye & guest Dr. John Glossner discuss the following:
- Dr. Glossner, we last talked in early November. For the benefit of our listeners, can you please provide a brief synopsis again on what the HSA Foundation is.
- In November, we also talked about what the Foundation calls Academic Centers of Excellence. Please elaborate again on what these are, and how does a higher educational institution become one?
- You mentioned then that Northeastern University in Boston was the first of these; in early December, two leading German universities also became Academic Centers of Excellence. Tell us about each and elaborate on some of the innovative HSA projects they’re working on.
- AMD, a founding member of the Foundation, recently provided a tutorial at an international conference on code generation and optimization. The title was ‘Updates in Heterogeneous Compute.’ Please share what you see as recent heterogeneous compute updates and developments.
- It appears that heterogeneous compute will be applicable for an array of apps. This can be everything from vision based IoT systems to mobile devices; desktops, high-performance computing (HPC) systems, AR/VR environments, and servers. So how will heterogeneous compute improve performance and power efficiency?
- How does HSA make life easier for IP and system designers?
John Glossner, Ph.D. is the President of The Heterogeneous System Architecture (HSA) Foundation and is a non-profit consortium of SoC IP vendors, OEMs, Academia, SoC vendors, OSVs and ISVs, whose goal is making programming for parallel computing easy and pervasive.
HSA members are building a heterogeneous computing ecosystem, rooted in industry standards, which combines scalar processing on the CPU with parallel processing on the GPU, while enabling high bandwidth access to memory and high application performance with low power consumption.
HSA defines interfaces for parallel computation using CPU, GPU and other programmable and fixed function devices, while supporting a diverse set of high-level programming languages, and creating the foundation for next-generation, general-purpose computing.
Glossner currently serves as CEO of General Processor Technologies.
hsaflogo2015
Website: www.hsafoundation.com
Social Media Links:
Facebook: facebook.com/thehsafoundation
Twitter: @hsafoundation
You’ll likely find the HSA software and toolchains quite useful and timeless
by Paul Blinzer, Embedded Computing Design: http://embedded-computing.com/guest-blogs/youll-likely-find-the-hsa-software-and-toolchains-quite-useful-and-timeless/#
Many people talk about hardware architecture as if it’s the most important part of a new platform. It’s true that hardware architecture is important for performance, which was discussed at length in a previous blog post. As a refresher, the pillars of the Heterogeneous System Architecture (HSA) are unified and shared virtual memory user-mode dispatch, platform atomics, architected signals, strict memory model, quality of service, and cache coherency.
However, including these features into the platform architecture is not for their own sake; it allows software to be written easily and to run efficiently. Even more so, it enables existing software to be ported easily and ideally automatically onto the new architecture.
While hardware typically has a limited lifespan of a few years at most, software may live almost forever. Sure, almost no one uses actual VT100 text terminals to communicate with the computer and the programs running back then, yet a lot of the software used today uses libraries and application frameworks that have their origin as far back as the 1970s. That software set the foundation of high-performance computing, the Internet, and security protocols used today, usually behind a shiny user interface. Even the good old VT100 terminal still lives on in the command lines of many popular operating systems (OSs) where the control sequences still behave as they did 40 years ago.
This is one reason why some platform architectures have endured over decades. While the hardware design and implementation may have changed substantially internally, the software-visible instruction set architecture (ISA) has endured and got incrementally extended without breaking backward compatibility to run the old programs, while other, more modern architectures were popular for a time but ultimately withered away as their performance advantage diminished. Software-compatible platforms came close enough to their levels to make binary software compatibility the overwhelming factor. Good examples are the x86 ISA, the ARM instruction architecture, or IBM’s System/360 ISA, the latter celebrating its 53rd anniversary and still in use.
How do you ensure the long-term viability of a platform architecture? You ensure that software written for the traditional architectures can run well and faster on it but also keep the software development tool chain like compilers, linkers, and development process familiar, so that the programmer doesn’t have to deal with two or more different software toolchains to get to performant software running on the platform.

Today’s extensive use of open-source software is an important factor, especially the GNU and LLVM-based compiler toolchains, readily available in open source repositories, and OSs like Linux, which are used as a foundation in embedded systems in various forms, sometimes “hidden away” (like in the case of Android). However, applications need to start and run without much delay, so it’s important that the compilation and time-expensive compiler code optimization to the accelerator doesn’t happen at the application’s load time (as often happens with many current accelerator APIs).
Most code optimization should happen once, when producing the application binary and then readily loaded and mapped to the accelerator. This needs a portable, accelerator-neutral ISA with fast transcription to the target accelerator ISA, instead of full compilation. Hence, it’s important to define a vendor-neutral ISA, which in the case of HSA is called HSA Intermediate Language (IL) or HSAIL. This IL represents a common ISA to target by compilers and is designed to be close to a data-parallel accelerator like a GPU, DSP or other hardware.
The source code written in a common high-level language like C++ or Python, be it an application framework or a popular application, will then produce code that’s defined in the IL. The compiler can apply all the extensive optimization steps to generate the intermediate code, which can then can be linked with other libraries, and even with modules written in different languages, such as C++, for some functions.
By integrating the IL as a binary section in the application binary (which is defined in an object format called BRIG), the program loader can then load both the host ISA and the accelerator code blocks in parallel and allow each to execute the program as written by the programmer without the end user seeing a difference from regular program load. Using the HSA run-time functionality, the software engineer can either target the HSA run-time directly or use an application interface or framework sitting on top of it, such as OpenCL.

But that’s not all. AMD has developed an open-source HSA run-time called Radeon Open Compute (ROCm) and added a portability layer called Heterogeneous Interface for Portability (HIP) that allows source code using proprietary CUDA APIs to compile and run on top of the ROCm run-time, while keeping source code compatibility. Alongside CodeXL, an open-source tool for profiling and debugging data parallel applications, this a powerful toolset to automatically port and run large application frameworks. While not using all ROCm features, it’s an easy way to take advantage of AMD’s HSA implementation without refactoring legacy code.
More information can be found in half-day HSA-focused tutorial at the HPCA/CGO conference in a couple of weeks.
New HSA Academic Centers of Excellence Undertake Research and Development of HSA-Compliant Technologies
By Dr. John Glossner, Computing Now: https://www.computer.org/web/hsa-connections/content?g=54930593&type=article&urlTitle=new-hsa-academic-centers-of-excellence-undertake-research-and-development-of-hsa-compliant-technologies
The Heterogeneous System Architecture (HSA) Foundation recently added two new HSA Academic Centers of Excellence – Technische Universitaet (TU) Darmstadt, and Friedrich-Alexander-University Erlangen-Nurnberg (FAU), both in Germany.
As mentioned in previous HSA Connections posts, HSA is a standardized platform design that unlocks the performance and power efficiency of the parallel computing engines found in most modern electronic devices. It allows developers to easily and efficiently apply the hardware resources—including CPUs, GPUs, DSPs, FPGAs, fabrics and fixed function accelerators—in today’s complex systems-on-chip (SoCs).
The research these universities are undertaking around HSA could potentially have significant impact for large-scale commercial use, particularly in the data center.
The Embedded Systems and Applications Group (ESA) of TU Darmstadt, for instance, is working with the HSA Foundation to explore how reconfigurable computing (specifically via Field-Programmable Gate Arrays or FPGAs), can be employed in processing units within the HSA framework.
Two key technologies developed by ESA are driving development: The Threadpool Composer system automatically assembles high-performance multi-threaded compute accelerators on FPGAs from existing hardware blocks, providing both pre-built hardware interfaces (e.g., to external memories or the host CPU), as well as software services (e.g., for dispatching compute jobs to the FPGA).
The joint research performed with the HSA Foundation also encompasses major development work on ffLink, a flexible high-performance PCI Express Gen3 x8 interface developed by ESA, which is capable of reaching a transfer rate of more than 7 GB/s between the FPGA accelerator and the host. Both Threadpool Composer and ffLink have been released as open source at https://git.esa.informatik.tu-darmstadt.de.
In the press release, Professor Andreas Koch, who heads the Embedded Systems and Applications Group (ESA) of TU Darmstadt, noted that the collaboration with the HSA Foundation is enabling them to make great progress on research that would have been extremely difficult to tackle without the additional insight provided by the industry partners.
The Department of Computer Science at FAU is currently focusing on integrating image processing accelerators in an FPGA and developing an HSA compliant interface. They are developing a self-designed processor core (packet processor) which is able to process requests and send them back to a host CPU using an HSA interface. The packet processor is then connected to the FAU’s own accelerator core and a PCI Express link to the system’s main memory.
To enable a fast interconnect to the host CPU, FAU is collaborating with TU Darmstadt’s Embedded Systems and Applications Group, which is providing a PCI Express core. FAU is also working on a technical prototype with the HSA Foundation; to support this work AMD, an HSA Foundation member, is providing the host system and technical help for using AMD HSA-enabled APUs, CPUs and GPUs.
The key takeaway from all of this?
FAU Professor Dietmar Fey summed it up nicely: “We’re now able to reach out to many industrial partners and work with them in establishing a standardization for heterogeneous computing platforms. It’s now becoming possible to combine fundamental research from a university with real world industry architectures and applications.”
The two universities are joining Northeastern University in Boston as HSA Academic Centers of Excellence. We’re looking forward to engaging on more projects with other universities worldwide to help make true heterogeneous processing a reality.
The First HSA Academic Center of Excellence
Posted on November 9, 2016, Entrepreneur Podcast Network: http://epodcastnetwork.com/the-first-hsa-academic-center-of-excellence/ (please visit website for podcast download)
Dr. John Glossner, President of HSA or The Heterogeneous System Architecture a non-profit whose goal is making programming for parallel computing easy and pervasive joins Enterprise Radio to discuss more about the foundation, the overall benefit and the new partnership.
Listen to host Eric Dye & guest Dr. John Glossner discuss the following:
- Describe the Foundation and how it got started.
- What are the overall benefits of joining the Foundation and adopting the membership?
- You recently announced new developments in heterogeneous architecture from Northeastern University. Can you tell us more about those developments?
- Any particular reason why your selected Northeastern for this partnership?
- Will the Foundation also be developing relationships with other key research universities worldwide? Have you identified those partnerships yet?
- Which industry constituents might be interested in the HSA Foundation’s work?
- How does the HSA Foundation development process work?
- How does one get involved and what is the criteria for being accepted into the Foundation?
John Glossner, Ph.D. is the President of The Heterogeneous System Architecture (HSA) Foundation and is a non-profit consortium of SoC IP vendors, OEMs, Academia, SoC vendors, OSVs and ISVs, whose goal is making programming for parallel computing easy and pervasive.
HSA members are building a heterogeneous computing ecosystem, rooted in industry standards, which combines scalar processing on the CPU with parallel processing on the GPU, while enabling high bandwidth access to memory and high application performance with low power consumption.
HSA defines interfaces for parallel computation using CPU, GPU and other programmable and fixed function devices, while supporting a diverse set of high-level programming languages, and creating the foundation for next-generation, general-purpose computing.
Glossner currently serves as CEO of General Processor Technologies.
SC16 to Feature Milestones in Heterogeneous System Architecture (HSA) Programming Languages, Open Standards, and Open Source Tools
Beaverton, OR, Nov. 9, 2016 – SC16, the international conference for high-performance computing (HPC), networking, storage, and analysis, will feature sessions that highlight recent heterogeneous system architecture (HSA) momentum. SC16 brings together the international supercomputing community to discuss the technologies that will shape the future of large-scale technical computing and data-driven science.
WHO: The HSA Foundation, a non-profit consortium whose goal is making programming for parallel computing easy and pervasive. Participants in the SC16 HSA sessions include:
- HSA Foundation Chairman and Senior Director of Radeon Open Compute for AMD Gregory Stoner
- AMD Senior Fellow Design Engineer and GPU CTO Ben Sander
- AMD Senior Member of Technical Staff Mayank Daga
WHAT: HSA is a standardized platform design supported by more than 40 technology companies and 17 universities that unlocks the performance and power efficiency of the parallel computing engines found in most modern electronic devices. HSA sessions at SC16 will highlight progress toward the Foundation’s goal of bringing true heterogeneous computing to platforms including vision based IoT systems, mobile devices, desktops, HPC systems, AR/VR environments, and servers. HSA-related sessions at SC16 include:
- Emerging Technologies: Programming High-Performance Heterogeneous Computing Systems with the Radeon Open Compute Platform (ROCm)
- Panel Discussion: Bringing About HPC Open-Standards World Peace
- Exhibitor Forum: Revolutionizing Large-Scale Heterogeneous HPC Systems with AMD’s ROCm Platform
WHERE: Salt Palace Convention Center in Salt Lake City
WHEN: Nov. 13-18, 2016; visit the SC16 website for specific session times
“Many HSA Foundation members such as AMD are now delivering a wide range of heterogeneous systems, including those based on HSA,” noted HSA Foundation President Dr. John Glossner. “It’s very exciting as one of the Foundation’s goals is to bring true heterogeneous computing to an array of platforms, some of which include Deep Neural Networks (DNN’s), vision based IoT systems, mobile devices, desktops, high-performance computing (HPC) systems, AR/VR environments, and servers.”
“The HSA Foundation is a strong proponent of open source development tools directly and through its member companies,” said HSA Foundation Chairman Greg Stoner. “AMD’s Radeon Open Compute Platform (“ROCm”) initiative, for example, brings a rich heterogeneous programming foundation for developers, and offers an array of development tools now freely available supporting HSA.”
Stoner added that ROCm via an HSA standardized object loader supports two compiler foundations:
- LLVM (Low Level Virtual Machine) compiler supports:
– HCC compiler for heterogeneous C++ with PSTL development
– HIP compiler for simply porting CUDA codes
– Continuum’s Anaconda with Numba for supporting Python development
– Khronos Group’s OpenCL C-based programming language
- SUSE GCC via enablement of HSA runtimes and HSA object format in conjunction with General Processor Technologies and Parmance
About the HSA Foundation
The HSA (Heterogeneous System Architecture) Foundation is a non-profit consortium of SoC IP vendors, OEMs, Academia, SoC vendors, OSVs and ISVs, whose goal is making programming for parallel computing easy and pervasive. HSA members are building a heterogeneous computing ecosystem, rooted in industry standards, which combines scalar processing on the CPU with parallel processing on the GPU, while enabling high bandwidth access to memory and high application performance with low power consumption. HSA defines interfaces for parallel computation using CPU, GPU and other programmable and fixed function devices, while supporting a diverse set of high-level programming languages, and creating the foundation for next-generation, general-purpose computing.
Follow the HSA Foundation on Twitter, Facebook and LinkedIn.
Contact:
Neal Leavitt
Leavitt Communications
(760) 639-2900
neal@leavcom.com
Platform and Hardware Requirements for HSA Technologies
by Paul Blinzer, September 8th, Embedded Computing Design: http://embedded-computing.com/guest-blogs/platform-and-hardware-requirements-for-hsa-technologies/#
Heterogeneous system architecture (HSA) is now a standardized platform design, supported by more than 40 technology companies and 17 universities, that unlocks the performance and power efficiency of the parallel computing engines found in most modern electronic devices. Spearheading HSA is the HSA Foundation, a non-profit consortium of SoC IP vendors, OEMs, Academia, SoC vendors, OSVs, and ISVs, whose goal is making programming for parallel computing easy and pervasive.

Briefly, HSA allows developers to easily and efficiently apply the hardware resources—including CPUs, GPUs, DSPs, FPGAs, fabrics, and fixed function accelerators—in today’s complex systems-on-chip (SoCs).
In this first of two posts, I’ll focus on platform and hardware requirements for HSA technologies; the second part will center on software and toolchains. Both will be discussed in depth at a tutorial at the upcoming 25th International Conference on Parallel Architectures and Compilation Architectures (PACT). The conference will be held from Sept. 11-15 in Haifa, Israel.
The architecture pillars of HSA
One of the key benefits of HSA is a set of platform architecture features and a programming model that software can depend on for parallel computing. Software using accelerators through an API like OpenCL, CUDA, or similar typically cannot assume that certain hardware features are available on every platform and so must either set a lowest common denominator or support many wildly different ways to essentially implement the same thing all over again to take advantage of an optional API feature while still supporting a lesser-equipped platform.
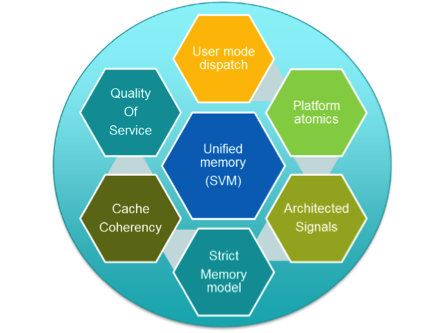
[Figure 1 | Pillars of HSA requirements]
HSA, in contrast, sets a requirement for a select few modern hardware features that make using the accelerator way more efficient and simplify the programming enormously, similar to what a CPU ISA like x86-64 or ARM has accomplished for compilers and application software development, with a reasonable expectation that a program will run efficiently on a platform with a particular processor and OS.
Let’s start with a brief list of requirements with a short explanation why they’re important.
Security and “quality of service”
An HSA accelerator is used as a peer processor to the CPU by the application, with all benefits and obligations. One of the key obligations is not allowing bad application code to do bad things to the system. Therefore, an HSA accelerator has a “user mode” ingrained for execution, where the operating system (OS) runtime sets strict policies at the hardware level for the accelerator. It can only access data and execute code that is part of the application process and if it accesses anything outside of the expected data, the OS runtime gets notified and can shut down the accelerator access by the application without affecting the rest of the system. A memory management unit (MMU) and other hardware to support it are therefore required by the HSA standard.
Shared virtual memory (SVM)
SVM allows the accelerator to access the application’s data directly and process it. That requires an MMU in hardware. HSA accelerators require it for system security reasons already, so no problem here.
Accelerators without SVM using OpenCL 1.x or the common CUDA API require the CPU to do a lot of work including parse application data, select/copy all data to/from the accelerator (which may need a dedicated buffer), and validate results. There is no concept of passing a pointer and allowing the accelerator to operate on shared memory. Often multiple data must be copied to the accelerator, but only one set of data is chosen. This can waste a lot of time to copy if we don’t know in advance which datasets are required. This copy overhead can seriously degrade the performance benefit of the accelerator.
This performance degradation is eradicated on an HSA accelerator. SVM allows the accelerator to parse and only access the application data it needs directly. As an added benefit, the accelerator and the CPU can access the same data in memory, avoiding unwanted duplicates.
Platform atomic operations
Anyone that has programmed with multithreaded code on a CPU knows how useful atomic operations are for ensuring that two threads can operate on the same data safely. Atomic operations are used in many different ways for implementing semaphores, mutexes, histograms, and many other tasks that require a particular order of execution or of access to work correctly. HSA compatible accelerators must support 32-bit or 64-bit atomics, as threads running on the CPU and on the accelerator operate and synchronize with each other very efficiently using atomic operations. Older accelerators without it always require arbitration using software APIs on the CPU. Software arbitration is very inefficient and these systems end up using far more CPU cycles that are better spent on other tasks.
HSA signals and doorbells
This is something special to HSA and a very significant feature for power-efficiency. You can consider these “atomics with benefits.” HSA Signals are data types created by the runtime that behave similar to atomically updated variables in memory. However, they allow the hardware to monitor and notify state changes, e.g. when a value is changed by an application thread or by an accelerator. One or more accelerators can update an HSA signal, listen and wait on a signal state change, and – if they have nothing else to do – go to sleep while waiting and be woken up immediately when something has changed. By using HSA signals, one accelerator can notify other accelerators directly that data is ready and these can start their processing immediately. If implemented fully, the CPU doesn’t need to perform any coordination and can stay asleep. This is a significant power saving feature because the only hardware that is needed for a task is only active when needed. HSA signals can be used easily everywhere in the software architecture and even HSA-based OpenCL implementations benefit.

User queues and dispatch
If you have programmed any accelerator using OpenCL or CUDA and followed in the debugger how it reaches the hardware, you will have noticed layers upon layers of software levels that the accelerator code and data must pass through until it finally reaches the hardware to be processed. HSA removes this inefficiency and cuts out the middle layers by defining a hardware-based user queue dispatch mechanism that can be directly accessed from the application runtime. The architected queuing language (AQL) that a packet processor of an accelerator uses allows any accelerator to either dispatch work to itself, to the CPU of the system to call OS runtime functions, or to other accelerators.
Cache coherency
Most HSA accelerators have caches that keep frequently used data close to the execution units. But since other processors in the system may also access the cached system memory, the application and the hardware must make sure that their content doesn’t get stale – especially in multithreaded execution. HSA accelerators therefore must provide mechanisms to keep the cached data current and either flush out pending data or invalidate cached data if other processors access the cached system memory. Cache coherency can be automatically enforced by hardware bus protocols or alternatively require instruction controls, which in the case of HSA is part of the definition.
With that, I hope I’ve made you interested enough to eagerly wait for the next blog entry, where I will touch on the HSA memory model HSAIL and how HSA integrates into today’s embedded systems.
HSA Foundation Aims for Broader Adoption of Coherent Memory Standard for Heterogeneous Processors
July 4, 2016, BDTi: http://www.bdti.com/InsideDSP/2016/07/05/HSAFoundation
Modern SoCs increasingly contain a variety of processing resources: one or more CPU cores and a GPU, often with a DSP, programmable logic, or one or multiple special-purpose co-processors for tasks such as computer vision. Properly harnessed, such heterogeneous processors often deliver impressive performance at low cost and low power consumption. But mapping applications onto heterogeneous processors is challenging. OpenCL, a specification standard language and runtime from the Khronos Group, enables the development of code that utilizes processing elements within a heterogeneous single- or multi-chip system. However, any processing efficiency gains derived from specialized computing elements can easily be negated by the added latency (not to mention incremental power consumption) incurred by copying data between computing elements.
Memory coherency among these diverse processing elements enables them to more efficiently share data via pointer-passing and queue-updating operations, versus bundling data and moving it via clumsy I/O operations through complex device drivers. Memory coherency has been common for some time in multi-CPU implementations; expanding the concept to GPUs, DSPs and other dissimilar architectures, however, is more challenging. OpenCL and other heterogeneous programming standards such as OpenMP and C++ AMP don’t make any attempt to standardize memory coherency, which requires the implementation of specific hardware features in each processing element. That mission has been taken up by the HSA (Heterogeneous System Architecture) Foundation, an industry group that has its origins in AMD’s proprietary Fusion System Architecture program (Figure 1).

Figure 1. The HSA Foundation boasts a sizeable, diverse membership list, but so far only AMD has chips implementing the organization’s standards.
Founded in mid-2012, the HSA Foundation released v1.0 of its specification suite in the spring of last year. And with newly announced, backward-compatible v1.1, according to foundation president Dr. John Glossner (who is also CEO of General Processor Technologies), the specification further expands beyond its AMD-centric foundations, supporting additional types of processor elements, as well as adding a number of requested features such as more flexible coherent memory access (Figure 2). SoC compatibility with the hardware aspects of the HSA specifications is becoming increasingly common, according to Glossner, and ARM for one agrees. In a recent briefing with Lead Mobile Strategist James Bruce and GPU Developer Tools Product Manager Anand Patel, the two ARM representatives noted that not only the latest Cortex-A73 and Mali-G71 but also the last several generations of ARM CPUs and GPUs are, in combination with newer CoreLink variants of ARM’s AMBA (Advanced Microcontroller Bus Architecture) interconnect, fully compatible with HSA’s memory coherency standards.


Figure 2. The initial v1.0 HSA specification was CPU- and GPU- specific, reflective of the AMD SoC platforms on which it was based (top), but the newer v1.1 spec is more vendor- and processor-agnostic, not to mention more flexible (bottom).
Hardware compatibility alone isn’t sufficient for full compliance with the HSA standards, however, which explains the current dearth of HSA-compliant SoCs in spite of significant industry backing for the HSA concept. At the core of HSA’s software scheme is HSAIL (the HSA Intermediate Language), an intermediate virtualized code abstraction created by HSA-cognizant compilers, which is then dynamically translated to a particular processor’s instruction set by a chip-vendor-supplied HSA Runtime layer. HSAIL-generating compilers are beginning to appear: AMD’s CLOC and the TUT (Tampere University of Technology) POCL both generate HSAIL from OpenCL source code, for example, while General Processor Technologies and Parmance have developed gccBrig, a BRIG (binary format) language front-end to GCC (the GNU Compiler Collection) that is a binary representation of HSAIL. Also, Continuum Analytics sponsors Numba, an open-source Python compiler with direct HSA support, specifically targeting GPU acceleration.
However, to date HSA Foundation creator AMD is the only member company to have developed an HSA Runtime, and then only for its latest Carrizo APU (accelerated processing unit, a CPU-GPU combo), which entered volume production at the end of last year. Even in AMD’s case, direct compilation to the end CPU and GPU instruction sets (versus to a HSAIL intermediate representation) is the preferred approach in AMD’s ROCm (Radeon Open Compute Platform). While we expect to see increased adoption of the HSA standards by AMD and other HSA Foundation member companies, some major chip suppliers are pursuing different approaches. Intel, for example, seems to prefer the Cilk scheme it’s championed, while NVIDIA continues to rely on its proprietary CUDA approach.
Researchers at Northeastern University recently validated that HSA, by removing the need for repeated data copy operations between heterogeneous processing elements, can dramatically improve algorithm performance– at least for a couple of algorithm examples (Figure 3). Three different memory access scenarios were considered: CL12 employs per-element buffers, while CL20 leverages a common albeit small shared virtual memory buffer; both employ only OpenCL. The full OpenCL-plus-HSA implementation, conversely, implements a unified memory space with fine-grained synchronization support, leverages regular pointers and doesn’t require copy operations. The evaluated FIR (finite impulse response) filter algorithm represents a memory-intensive streaming workload; AES (Advanced Encryption Standard) symmetric encryption and decryption conversely is a compute-intensive streaming workload. Glossner was also careful to point out that these results were measured on AMD’s Kaveri APU, which being a pre-HSA 1.0 device supports only limited coherent memory throughput.


Figure 3. Recent evaluations conducted by Northeastern University researchers highlight HSA’s performance-boosting potential in both memory-intensive (top) and compute-intensive (bottom) workloads, even with SoCs that aren’t fully HSA-optimized (A Comprehensive Performance Analysis of HSA and OpenCL 2.0, Proceedings of the 2016 International Symposium on Program Analysis and System Software, April 2016).
Any performance loss due to the HSAIL-plus-HSA Runtime multi-layer abstraction will, Glossner feels, be more than counterbalanced by the significant performance boost delivered by HSA’s support for full memory coherency between heterogeneous processing elements. AMD Carrizo APU-based systems are now shipping from PC OEMs such as ASUS, Dell and Lenovo, and Glossner anticipates additional HSA support announcements to arrive shortly from other SoC and IP core providers. Until then, though, HSA will remain an approach with industry-wide potential but limited deployment.
For more information on the HSA Foundation, see the following two videos from the May 2016 Embedded Vision Summit (Video 1 and 2).
AT&T adds fiber markets, Sprint weighs in on small cells … 5 things to know today
By Martha DeGrasse, June 27th, RCR Wireless News: http://www.rcrwireless.com/20160627/carriers/att-adds-fiber-markets-sprint-weighs-in-on-small-cells-5-things-to-know-today-tag4
1. AT&T is promising business customers download and upload speeds of up to 1 gigabit per second. The company said today that it has expanded its AT&T Fiber service in Texas, Tennessee, South Carolina and Oklahoma. In addition, the carrier is expanding AT&T Fiber in several major cities, including Los Angeles, San Francisco, San Diego and Fresno, California; Miami; Dallas and El Paso, Texas; and Louisville, Kentucky.
AT&T also said it is launching nationwide voice-over-IP service through AT&T Business Fiber. The service is available in 180 U.S. cities, most of which are located in the South, Southeast and Central U.S., or on the West Coast.
2. Sprint said it is not concerned about the pace at which its small cell rollout is proceeding. The company’s top executives report that “the permitting and approval stage for its small cell deployment has been ahead of expectations,” according to Wells Fargo analyst Jennifer Fritzsche, who met with Sprint’s CEO, CFO and CTO last week. In a separate meeting, Mobilitie CEO Gary Jabara told Fritzsche’s team that Mobilitie is cooperating closely with local authorities as it deploys on Sprint’s behalf, and that there have been no cities that have put a complete stop to small cell deployments.
Sprint said last summer that it planned to deploy tens of thousands of small cells, and so far has not released a public update to that number. Jabara said this spring that Mobilitie has deployed fewer than 2,000 small cells to date.
3. Apple is now licensing patents from Huawei, according to The Wall Street Journal. Citing “a person familiar with the matter,” the paper did not specify what type of patent Huawei reportedly licensed to Apple. Noting that Huawei spent $9.2 billion on research and development last year vs. Apple’s $8.1 billion, the report said the Chinese company is also the world’s largest filer of international patent applications under the Patent Cooperation Treaty.
In the smartphone market, Huawei is a distant third behind Samsung and Apple, but the company has made it clear that it wants to compete head-on with the two market leaders. Huawei already dominates the market for wireless infrastructure, where it holds a leading position despite political pressures that keep Huawei’s gear out of U.S. wireless networks.
4. Huawei’s smartphone ambitions may include a proprietary operating system. The company has reportedly hired former Apple designer Abigail Brody to work on an operating system that would be an alternative to Android if Huawei’s relationship with Android developer Google takes a turn for the worse. Other smartphone makers have tried to develop proprietary operating systems, but so far application developers have been reluctant to invest time and money in apps for platforms other than Android and iOS.
5. The Heterogeneous System Architecture Foundation has released a specification the group says will make it easier to integrate digital solutions that use disparate hardware. HSA is a standardized platform design supported by more than 40 technology companies and 17 universities. The new spec adds multivendor architecture support, which means manufacturers will be able to combine IP blocks from more than one vendor. One of the group’s primary goals is to enable heterogeneous computing for vision-based “internet of things” systems.
Toward a Hardware-Agnostic World: HSA Foundation Releases Specification v1.1
By Jim Turley, EE Journal: http://www.eejournal.com/archives/articles/20160601-hsa/
I think there’s something great and generic about goldfish. They’re everybody’s first pet. – Paul Rudd
It’s finally happened: processors are now completely generic and interchangeable.
Might as well go home, CPU designers. There is no differentiation left to exploit. All of your processor architectures, instruction sets, pipelines, code profiling, register files, clever ALUs, bus interfaces – all of it is now as generic and substitutable as 80’s hair band drummers. Your entire branch of technology has been supplanted by some programmers.
Okay, so maybe it’s not quite that dire. But we’re getting there.
You have the HSA Foundation to thank for that. Their job is to make CPUs, DSPs, GPUs, VLIW machines (and pretty much anything else that can execute code) totally interchangeable. In the big SWOT analysis of hardware resources, the CPU becomes a “don’t care.” That is, HSA (which stands for Heterogeneous Systems Architecture) tries to make any code execute on any processor, regardless of its architecture, instruction set, or number of cores. They’ll let you run your operating system on a DSP, your graphics code on an integer CPU, and your signal-processing algorithms on a GPU. Hardware is hardware; just write your code and let HSA sort it out.
At least, that’s the promise the group has been making for the past few years. It’s what Steve Jobs would’ve called, “a big hairy audacious goal.” Hey, let’s treat all programming languages the same and all hardware engines the same. Programmers can write their source code in whatever language(s) they prefer, and let it run on whatever hardware they have lying around. Most of all, HSA allows you to mix different processor architectures together (that’s the “heterogeneous” part) so that you can, for example, run a multicore x86 processor alongside a cluster of ARM cores, next to a gaggle of nVidia GPUs. Pay no attention to how those processors are interconnected, or how many there are, or even what type of chip you’ve got. It’s all good! Throw ’em all together and let the software sort ’em out!
Sound like magic? Kind of. Sound like a bad idea that’s already been done to death by a thousand different university students who think they’ve stumbled on a fantastic (and original) idea? You’d be correct there, too. The idea of a universal hardware platform is hardly new, and the road to hardware independence is paved with other people’s venture capital. Java is about the only example of hardware-independent software that made any kind of a dent in the industry – but dents can be good or bad.
But wait a sec – isn’t Java already hardware agnostic (as in, “we don’t believe hardware exists”), and if so, why do we need another one? And for that matter, isn’t all code written in C++ or Python or BASIC or any decent language also platform-independent? Wasn’t that the whole idea of high-level languages? What problem are we actually solving here, and hasn’t it already been solved anyhow?
Well, yes and no. Java bytecode is (ahem) more or less transportable across different CPU architectures… assuming the architecture in question has its own bytecode interpreter or JIT or equivalent translator. And C code is certainly transportable… right up until it’s compiled. At that point, it’s very hardware-specific. But neither of these examples really ignores the underlying architecture of the chip you’re programming. Nobody writes C code without knowing if it’s intended for a conventional CPU, or a DSP, or a graphics processor. Same goes for any other programming language. You always want to know something about the processor it’s going to run on, even if you’re not bit-twiddling individual configuration registers.
So HSA wants to abstract-away that last vestige of processor prejudice. This is particularly important and useful in today’s systems that mix and match so many different kinds of processors. How cool would it be to write your C or Python and truly not care how many processors, or of what type, were ultimately going to host it?
The core of HSA’s technology, as with so many other “universal hardware platforms,” is an intermediate virtual machine. In other words, you’re writing code for an imaginary CPU, and HSA-compliant tools then convert that to actual machine code for the hardware you really have. It’s not too different in concept from any other compiler, and pretty similar to the way Java is compiled.
This intermediate layer is called HSAIL (HSA Intermediate Language), and it’s specified just like a real CPU with a real instruction set and everything. In fact, you can download the HSAIL specification for free and build your own HSA-compliant toolchain if you like. The HSA Foundation would probably be happy to encourage you.
The only hardware requirement to using HSA is that all the processors in your system must share a single, cache-coherent memory space. That’s important, and it’s non-negotiable. It’s the key feature that allows HSA tools to allocate and reallocate code segments among processors. When everyone shares a memory map, a pointer is a pointer, regardless of who created it or who dereferences it. Cache coherence is also mandatory, for much the same reason. The results of one processor’s calculations have to be universally accessible to all the other processors, without careful planning or message-passing.
In fact, that lack of planning and messaging is one of HSA’s strengths, though it’s hardly unique. The group recently ran some benchmarks comparing HSA-compliant code with OpenCL (which also tolerates heterogeneous hardware resources). In HSA’s testing, their code did far better, of course, and often by orders of magnitude.
An FIR filter, for example, ran about 10x to 100x faster than the equivalent OpenCL code. Pretty impressive. But can a toolchain really make that much difference? Depends what you’re comparing it to. Software FIR filters are very memory-intensive, and the OpenCL implementation handles its data structures in a “pass by value” method. In other words, it copies all of the data from one processor’s memory space to another’s. That wastes a huge amount of time (and consumes a lot of memory). HSA, in contrast, does “pass by reference.” Voila – you’ve saved a mountain of time with a different toolchain.
So who’s behind the HSA Foundation? Who stands to gain from this? Like many consortia, HSA draws its members from industry. On the CPU side, they’ve got support from AMD, ARM, and Imagination Technologies. So there’s x86, ARM, and MIPS represented, as well as Radeon, Mali, and PowerVR graphics. Toshiba, Texas instruments, Tensilica, Analog Devices, Ceva, Synopsys (with ARC), and other second-tier CPU vendors also participate. A lot of universities are contributing manpower, and several research laboratories are represented, too. So a good cross-section of interested parties overall.
Does it really work? It seems to, at least in early testing. The group has just released version 1.1 of its specification (also available for free download), and they’re adding support for more compilers and more processors. Compared to v1.0, HSA v1.1 is now more closely compatible with gcc. It’s a long and tricky process, but the HSA Foundation seems to be making real progress toward making CPU designers obsolete.